Text-zu-Video Grundlagen
Wie die Videogenerierung auf PonPon funktioniert: Text-zu-Video vs. Bild-zu-Video, die Auswahl von Modellen wie Veo 3.1, Sora 2 und Kling 3.0 sowie die Tabs Bearbeiten und Bewegungssteuerung.
Der Videogenerator verwandelt einen Prompt – oder ein Bild – in einen animierten Clip. Er hat drei Tabs: Video erstellen, Video bearbeiten und Bewegungssteuerung. Die meiste Arbeit beginnt unter „Erstellen“.
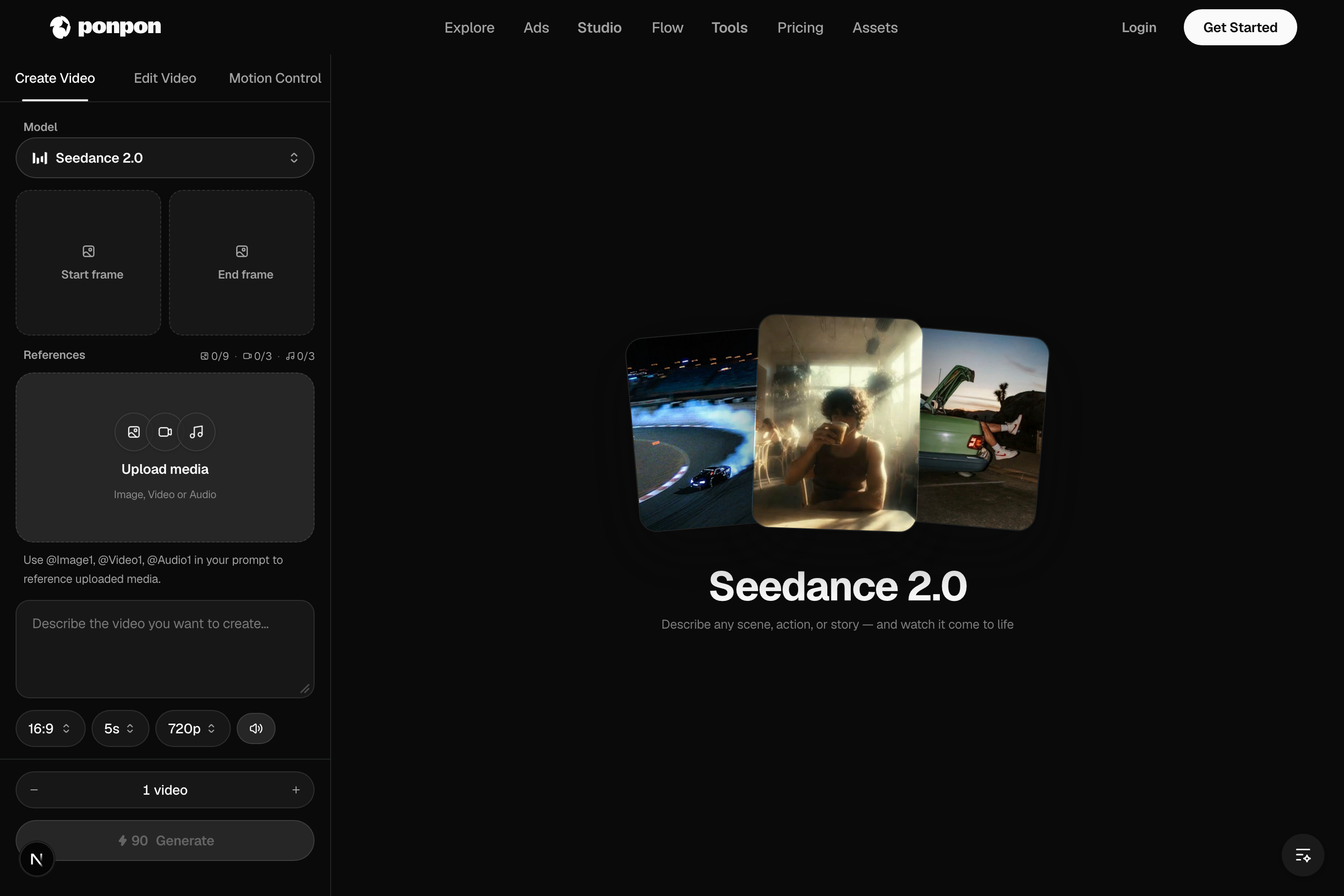
Ein Generator, vier Eingabemodi
Es gibt keinen Modusschalter – PonPon erkennt anhand deiner Eingabe, was du möchtest:
- Text-zu-Video – nur ein Prompt, sonst nichts. Maximale Freiheit; das Modell erfindet jeden Frame.
- Bild-zu-Video – lade einen Startframe hoch, und das Modell animiert ihn als ersten Frame. Maximale Kontrolle über das Aussehen.
- Start → End-Morphing – füge zusätzlich einen Endframe hinzu, und der Clip geht von einem Bild zum anderen über.
- Referenz-zu-Video – hänge auf einem geeigneten Modell Referenzbilder/-videos an, um ein Motiv oder einen Stil in die Aufnahme zu übertragen.
Beschreibe Bewegung, nicht nur eine Szene
Ein Standbildprompt beschreibt einen Moment. Ein Videoprompt beschreibt einen Moment, der sich verändert – Motiv, Aktion, Kamera und Tempo:
Ein Surfer paddelt hinaus und steht bei Sonnenaufgang auf einer Welle auf, die Kamera verfolgt ihn auf Wasserhöhe, Gischt fängt das Licht. Weiche, kinematische Bewegung.
Ein Modell auswählen
Die Auswahl besteht aus einer Reihe von Chips. Jedes hat eine klare Stärke:
- Veo 3.1 – die kontrollierteste Kamerasprache plus natives Audio. Ein großartiger Allrounder. Veo 3.1 Fast erzeugt denselben Look schneller.
- Sora 2 – erstklassige Physik und Texturealismus, mit synchronisiertem Audio.
- Kling 3.0 – präzise Bewegung, Lippensynchronisation und Multi-Shot-Storytelling (mehrere Kameracuts in einer Generierung).
- Seedance 2.0 – schnell und ausdrucksstark, vertikal ausgerichtet, mit Audio-visueller Beat-Synchronisation. Seedance 2.0 Fast ist noch schneller.
- HappyHorse – das vielseitigste Modell: Text, Bild, Referenz und Bearbeitungs-Pipelines, mit vielen Referenzcharakteren und nativem Audio.
Seitenverhältnis, Dauer, Auflösung, Audio
- Seitenverhältnis – 16:9 für YouTube, 9:16 für TikTok / Reels / Shorts, 1:1 für den Feed (ausgeblendet, wenn du mit einem Bild startest).
- Dauer & Auflösung – die verfügbaren Optionen hängen vom Modell ab.
- Audio – bei audio-fähigen Modellen erzeugt ein Toggle Ton zusammen mit dem Bild; manche Modelle (wie HappyHorse) enthalten Audio immer.
Über „Erstellen“ hinaus: Bearbeiten und Bewegungssteuerung
- Video bearbeiten – gib einen vorhandenen Clip und einen Prompt ein, um ihn neu zu gestalten oder zu verändern (Video-zu-Video), optional mit Beibehaltung des Originaltons.
- Bewegungssteuerung – steuere ein statisches Charakterbild mit der Bewegung aus einem Referenz-Video und wähle, ob der Charakter dem Bild oder dem Video folgt.
Nach dem Rendering
- Reihe Einstellungen aneinander und führe sie in Flow erneut aus, oder erstelle ein mehrszeniges Werk in Studio.
- Füge im Audio-Studio einen Voiceover, Musik oder Soundeffekte hinzu.
Für die tiefere Methodik – Kamerasprache, Shot-Struktur und häufige Korrekturen – lies Prompting für Video.
Verwandte Artikel
- Dein erstes KI-VideoSchritt für Schritt: Anmelden, Prompt schreiben, Modell auswählen, Seitenverhältnis, Dauer und Auflösung festlegen, generieren und dein erstes KI-Video auf PonPon herunterladen.
- Prompts für VideoEine praktische Methode für KI-Video-Prompts auf PonPon: Shot-Aufbau, die Kamerabewegungen, die die Modelle verstehen, Tempo, modellspezifische Tipps und häufige Fehler beheben.
- Bildgenerierung — GrundlagenSchreibe einen guten Bild-Prompt, wähle zwischen Modellen wie GPT Image 2, Nano Banana Pro und Seedream 5.0, nutze Referenzbilder und bearbeite Ergebnisse mit den Annotierungswerkzeugen.