打造一个 AI 网红
用你自己的照片打造一个精致、一致的 AI 网红形象:用 Muse 把一张自拍变出一整套贴合人设的造型,再让它动起来、赋予声音——在 PonPon 上从头做到尾。
AI 网红就是一个精致、一致的网络人设——每条帖子里都是那张可辨认的同一张脸,由 AI 来造型和制作。在 PonPon 里打造它最切实可行的方式,是从你自己的照片出发,让 AI 来负责造型、"拍摄"和动态,这样你不用进影棚就能发出源源不断、贴合人设的内容流。整件事的核心就是一致性:每条帖子都得让人一眼认出是同一个人。
第 1 步——从一张过硬的基础照片开始
一切都以一张脸为基准,所以先从一张干净、正面的自拍开始:光线均匀、脸部完整可见、不戴墨镜、不带浓重阴影。Muse 会读取这张脸,并在它生成的每一种造型里都把它保留下来——源图越清晰,你整个内容流就越一致。
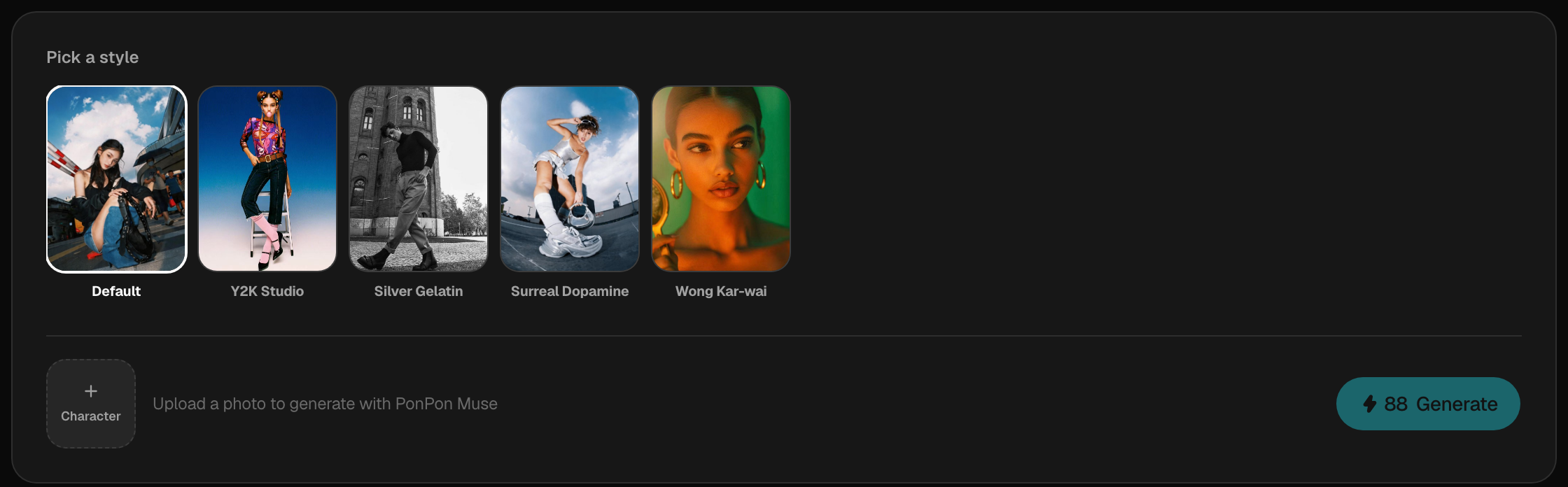
第 2 步——用 Muse 生成一整套一致的造型
打开 Muse——PonPon 的引导式人像处理流程。照片只需上传一次,然后从它的预制提示词库里搭建一套造型:按关键词搜索来匹配某种调性(街头、时尚大片、Y2K、电影感……),或者当你只想要更多选择时,随机摇一批出来。Muse 在每一张里都保留你这张脸,于是一次上传就能变成几十张协调、贴合人设的人像。各种风格、批量预设和最佳照片技巧,参见 Muse 指南。
想要预设没覆盖到的造型?开放的图片生成器,把你的照片作为参考放进去——或者用 Nano Banana Pro 做保留身份的编辑——都能在守住同一张脸的同时把这套造型扩展开。参见图片提示词写作。
第 3 步——让这个人设活起来
把最好的几张静态图变成短片。把一张人像放进视频生成器的 Start frame 起始帧,做出一个动态镜头;或者让这个人设开口说话:先生成一段配音,再驱动一次数字人对口型,让口型与话语对上。Kling 3.0 在对口型和对话上很强。参见图生视频指南。
她看向镜头,带着温暖的微笑打招呼,放松而自然,头部有轻微的动作。竖屏 9:16,5 秒。
第 4 步——赋予声音并发布
挑一个语音并保持一致——声音也是身份的一部分。在 Studio 里拼装多镜头作品,加上一层音乐垫底,导出 9:16 用于 Reels / TikTok。
常见修复
| 问题 | 试试这样做 |
|---|---|
| 脸在不同造型间发生变化 | 换一张更清晰、正面打光的基础照片——Muse 读不清的脸就守不住 |
| 造型感觉重复 | 摇一批随机造型,或搜一个不同的关键词来换些新预设 |
| 某个预设让脸变形了 | 在换预设之前先换一张更干净的基础照片;源图质量解决的问题比换预设更多 |
| 声音在不同帖子间不一样 | 锁定一个语音,每次都复用它——声音也是身份的一部分 |
| 对口型看起来不对 | 用一张清晰的正面人像,配一个对口型能力强的模型,比如 Kling 3.0 |
| "Photos of real people aren't supported" | 某个视频模型的隐私过滤——要让真人脸动起来,请改用 Kling 3.0 或 Veo 3.1 |
让它长期保持一致
- 永远从同一张基础脸出发,让每一种造型都读起来是同一个人。
- 复用同一个语音,以及定义你审美风格的同一小撮 Muse 关键词。
- 把你最好的几种造型保存为参考图,这样发一条新帖永远只差一次生成。
相关文章
- Muse 人像PonPon Muse 能把一张自拍变成保留你本人面容的超写实时尚人像。讲解它的工作原理、八种风格、批量预设、双人模式,以及如何拿到最佳效果。
- 数字人与对口型在 PonPon 上让一个角色开口说话:用 Kling 3.0 让对口型根据音轨驱动一张脸、声音从何而来、一个实战示例、源素材技巧,以及如何与配音译制搭配。
- 图生视频指南让你已有的一张静态图动起来:挑一张过硬的源图、用好起始帧和结束帧、写运动(而非场景),并为 PonPon 上的图生视频选对模型。
- 图片提示词写作一套实用的 PonPon AI 图片提示词方法:可靠的结构、由弱到强的改写、模型能理解的风格与光线词汇、参考图,以及常见问题的修复。