Conceitos básicos de texto para vídeo
Como funciona a geração de vídeo no PonPon: texto para vídeo vs. imagem para vídeo, escolher modelos como Veo 3.1, Sora 2 e Kling 3.0, e as abas Edit e Motion Control.
O gerador de vídeo transforma um prompt — ou uma imagem — em um clipe em movimento. Ele tem três abas: Create Video, Edit Video e Motion Control. A maior parte do trabalho começa em Create.
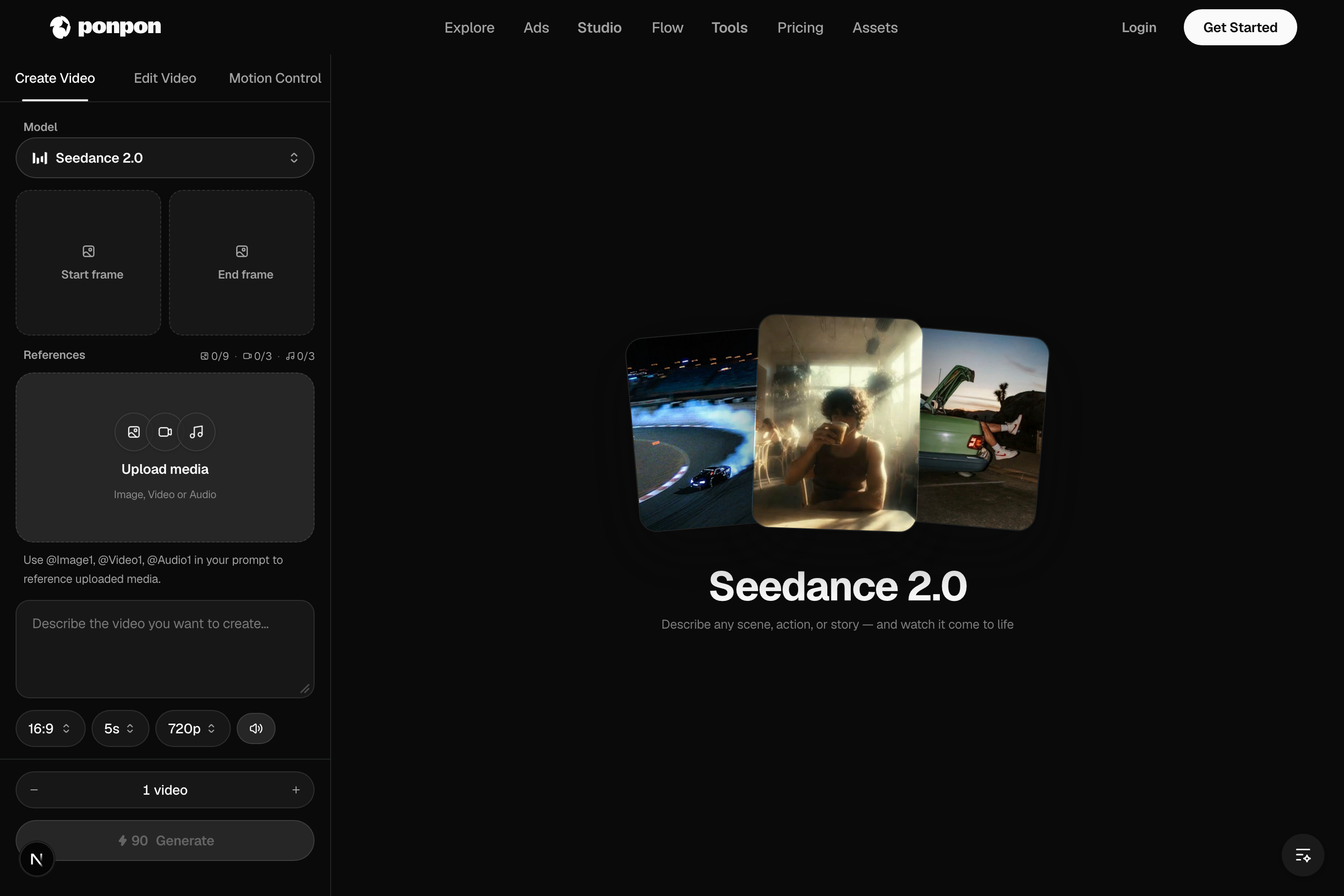
Um gerador, quatro modos de entrada
Não há um botão de modo — o PonPon deduz o que você quer pelo que você dá:
- Texto para vídeo: só um prompt e nada mais. Liberdade máxima; o modelo inventa cada quadro.
- Imagem para vídeo: envie um Start frame (quadro inicial) e o modelo o anima como primeiro quadro. Controle máximo do visual.
- Transição início → fim: adicione também um End frame (quadro final) e o clipe faz a transição de uma imagem para a outra.
- Referência para vídeo: anexe imagens/vídeos de referência em um modelo compatível para levar um sujeito ou estilo à tomada.
Nota
Você nunca escolhe um modo — os campos Start frame e End frame e quaisquer anexos de referência decidem por você. Se você já tem uma imagem de personagem ou produto que ama, comece por um quadro; se está explorando, comece pelo texto.
Escreva movimento, não só uma cena
Um prompt de imagem fixa descreve um momento. Um prompt de vídeo descreve um momento que muda: sujeito, ação, câmera e ritmo:
Um surfista rema mar adentro e fica de pé sobre uma onda ao amanhecer, a câmera o acompanha em paralelo na altura da água, a espuma capta a luz. Movimento suave e cinematográfico.
Escolher um modelo
O seletor é uma fileira de fichas. Cada um tem uma força clara:
- Veo 3.1: a linguagem de câmera mais controlável, mais áudio nativo. Um ótimo coringa. Veo 3.1 Fast esboça o mesmo visual mais rápido.
- Sora 2: física e realismo de texturas de ponta, com áudio sincronizado.
- Kling 3.0: movimento preciso, sincronia labial e narrativa de várias tomadas (vários cortes de câmera em uma geração).
- Seedance 2.0: rápido e expressivo, prioriza o vertical, com sincronia audiovisual no ritmo. Seedance 2.0 Fast é ainda mais rápido.
- HappyHorse: o mais versátil: fluxos de texto, imagem, referência e edição, com muitos personagens de referência e áudio nativo.
Proporção, duração, resolução, áudio
- Proporção: 16:9 para o YouTube, 9:16 para TikTok / Reels / Shorts, 1:1 para o feed (oculta ao começar por uma imagem).
- Duração e resolução: as opções dependem do modelo.
- Áudio: em modelos com áudio, um interruptor gera som junto com a imagem; alguns modelos (como o HappyHorse) sempre o incluem.
Dica
Mantenha os primeiros renders curtos e na resolução padrão. O movimento se lê igual a 720p e a 1080p, então você julga se uma tomada funciona por uma fração dos créditos antes de partir para a versão longa e em alta resolução.
Além do Create: Edit e Motion Control
- Edit Video: forneça um clipe existente e um prompt para reestilizá-lo ou modificá-lo (vídeo para vídeo), mantendo o áudio original se quiser.
- Motion Control: conduza uma imagem de personagem fixa com o movimento de um vídeo de referência, escolhendo se o personagem segue a imagem ou o vídeo.
Depois do render
- Ordene tomadas e rode-as de novo no Flow, ou monte uma peça de várias cenas no Studio.
- Adicione narração, música ou efeitos sonoros no estúdio de áudio.
Para o método mais a fundo — linguagem de câmera, estrutura de tomada e correções comuns — leia Como escrever prompts de vídeo.
Artigos relacionados
- Seu primeiro vídeoPasso a passo: entre, escreva um prompt, escolha um modelo, defina proporção, duração e resolução, gere e baixe seu primeiro vídeo com IA no PonPon.
- Prompts de vídeoUm método prático para prompts de vídeo com IA no PonPon: estrutura de tomada, os presets de câmera que os modelos entendem, ritmo, dicas por modelo e como corrigir falhas comuns.
- Geração de imagensEscreva um bom prompt de imagem, escolha entre modelos como GPT Image 2, Nano Banana Pro e Seedream 5.0, use imagens de referência e edite resultados com as ferramentas de anotação.