Conceptos básicos de texto a video
Cómo funciona la generación de video en PonPon: texto a video vs. imagen a video, elegir modelos como Veo 3.1, Sora 2 y Kling 3.0, y las pestañas Edit y Motion Control.
El generador de video convierte un prompt —o una imagen— en un clip en movimiento. Tiene tres pestañas: Create Video, Edit Video y Motion Control. La mayoría del trabajo empieza en Create.
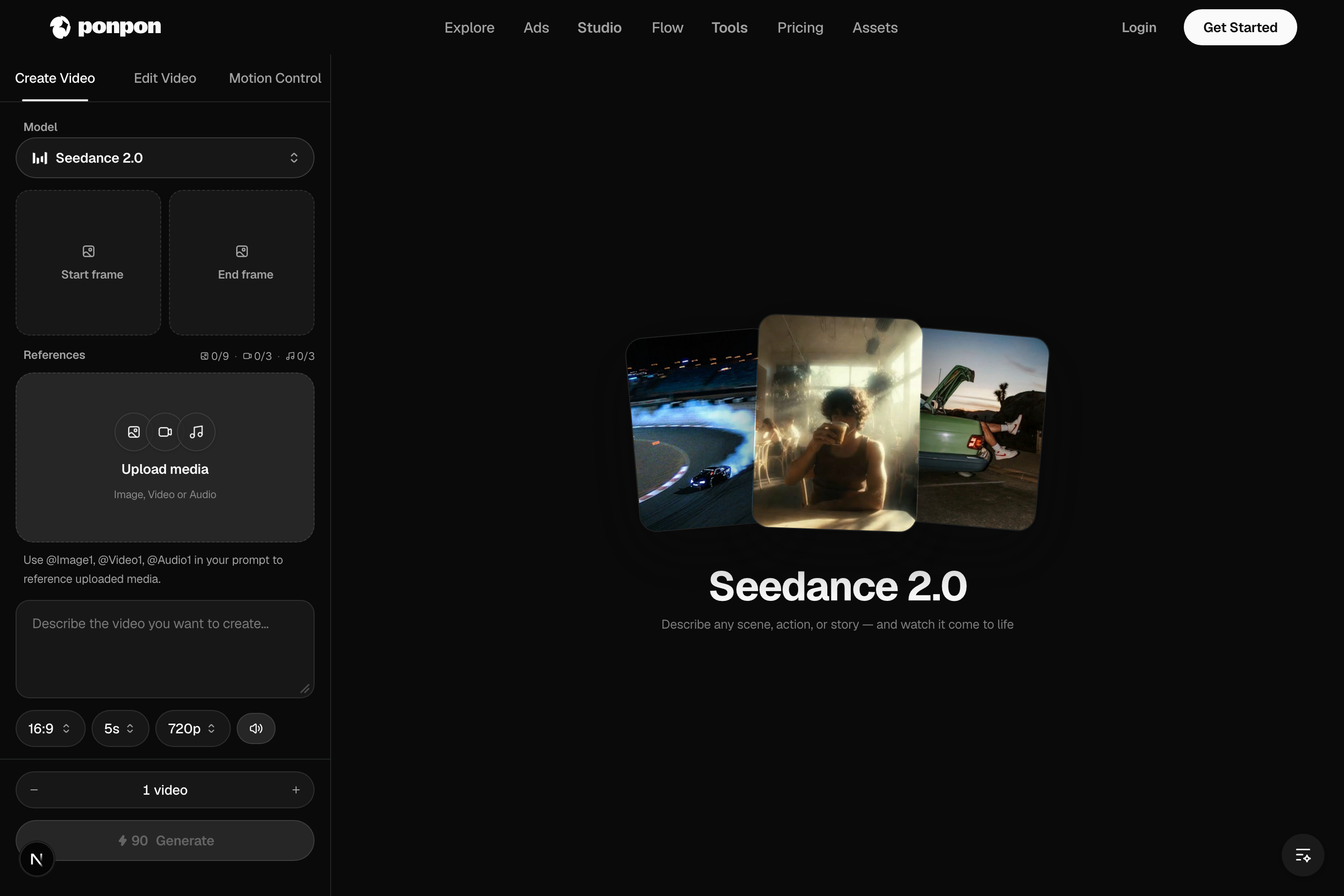
Un generador, cuatro modos de entrada
No hay un interruptor de modo: PonPon deduce lo que quieres a partir de lo que le das:
- Texto a video: solo un prompt y nada más. Máxima libertad; el modelo inventa cada fotograma.
- Imagen a video: sube un Start frame (fotograma inicial) y el modelo lo anima como primer fotograma. Máximo control del aspecto.
- Transición inicio → fin: añade también un End frame (fotograma final) y el clip transiciona de una imagen a otra.
- Referencia a video: adjunta imágenes/videos de referencia en un modelo compatible para llevar un sujeto o estilo a la toma.
Escribe movimiento, no solo una escena
Un prompt de imagen fija describe un momento. Un prompt de video describe un momento que cambia: sujeto, acción, cámara y ritmo:
Un surfista rema mar adentro y se pone de pie sobre una ola al amanecer, la cámara lo sigue en paralelo a la altura del agua, la espuma atrapa la luz. Movimiento suave y cinematográfico.
Elegir un modelo
El selector es una fila de fichas. Cada uno tiene una fortaleza clara:
- Veo 3.1: el lenguaje de cámara más controlable más audio nativo. Un gran todoterreno. Veo 3.1 Fast bosqueja el mismo aspecto más rápido.
- Sora 2: física y realismo de texturas de primera, con audio sincronizado.
- Kling 3.0: movimiento preciso, sincronización de labios y narrativa de varias tomas (varios cortes de cámara en una generación).
- Seedance 2.0: rápido y expresivo, prioriza el vertical, con sincronización audiovisual al ritmo. Seedance 2.0 Fast es aún más rápido.
- HappyHorse: el más versátil: flujos de texto, imagen, referencia y edición, con muchos personajes de referencia y audio nativo.
Relación de aspecto, duración, resolución, audio
- Relación de aspecto: 16:9 para YouTube, 9:16 para TikTok / Reels / Shorts, 1:1 para el feed (se oculta al empezar desde una imagen).
- Duración y resolución: las opciones dependen del modelo.
- Audio: en los modelos con audio, un interruptor genera sonido junto con la imagen; algunos modelos (como HappyHorse) siempre lo incluyen.
Más allá de Create: Edit y Motion Control
- Edit Video: introduce un clip existente y un prompt para reestilizarlo o modificarlo (video a video), conservando opcionalmente el audio original.
- Motion Control: dirige una imagen de personaje fija con el movimiento de un video de referencia, eligiendo si el personaje sigue a la imagen o al video.
Después del render
- Ordena tomas y vuelve a ejecutarlas en Flow, o construye una pieza de varias escenas en Studio.
- Añade locución, música o efectos de sonido en el estudio de audio.
Para el método más a fondo —lenguaje de cámara, estructura de toma y soluciones comunes— lee Cómo escribir prompts de video.
Artículos relacionados
- Tu primer video con IAPaso a paso: inicia sesión, escribe un prompt, elige un modelo, ajusta relación de aspecto, duración y resolución, genera y descarga tu primer video con IA en PonPon.
- Prompts de videoUn método práctico para prompts de video con IA en PonPon: estructura de toma, los presets de cámara que entienden los modelos, ritmo, consejos por modelo y cómo arreglar fallos comunes.
- Generación de imágenesEscribe un buen prompt de imagen, elige entre modelos como GPT Image 2, Nano Banana Pro y Seedream 5.0, usa imágenes de referencia y edita resultados con las herramientas de anotación.