打造一個 AI 網紅
從你自己的照片打造一個精緻、一致的 AI 網紅形象:用 Muse 把一張自拍變成源源不絕、風格統一的整套造型,再讓它動起來並賦予聲音——在 PonPon 上從頭到尾完成。
AI 網紅是一個精緻、一致的線上人物形象——在每一則貼文裡都是同一張能被認出來的臉,由 AI 來打理造型與產製。在 PonPon 裡最務實的做法,是從你自己的照片出發,讓 AI 接手造型、「拍攝」和動態,這樣你不需要攝影棚,就能發出源源不絕、風格統一的內容。整件事的核心就是一致性:每一則貼文都必須讓人讀成同一個人。
第一步——從一張好的基底照片開始
一切都以一張臉為核心,所以先準備一張乾淨、正面的自拍:光線均勻、臉部完整可見,不要墨鏡或濃重的陰影。Muse 會讀取那張臉,並在它生成的每一套造型裡保留它——源圖越清晰,你整套內容就越一致。
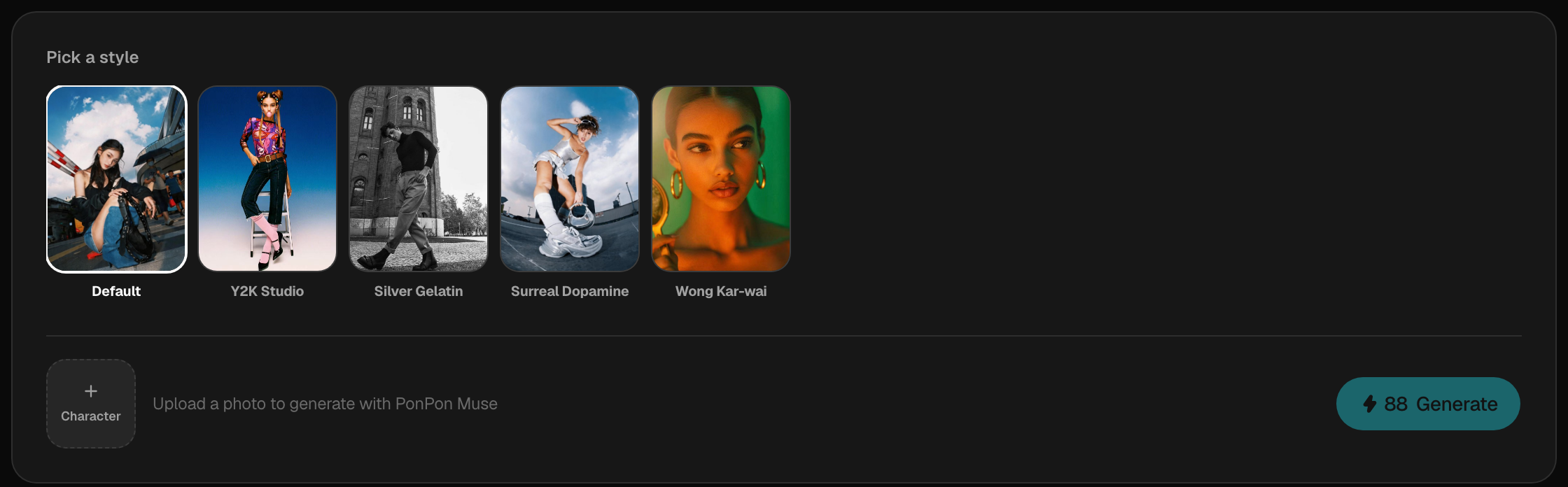
第二步——用 Muse 生成一致的整套造型
開啟 Muse——PonPon 的引導式人像處理流程。把你的照片上傳一次,接著用它的預製提示詞庫建立一整套造型:用關鍵字搜尋來比對某種氛圍(街頭、雜誌風、Y2K、電影感……),或者只想要更多選項時,就抽一批隨機結果。Muse 會在每一張裡都保留你的臉,所以單次上傳就能變成數十張協調、風格統一的人像。各種風格、批次預設,以及最佳照片建議,請參見 Muse 指南。
想要預設裡沒有的造型?開啟圖片生成器,把你的照片放進去當作參考——或用 Nano Banana Pro 做保留身分特徵的編輯——就能在守住同一張臉的同時擴充這套造型。參見圖片提示詞寫作。
第三步——讓這個人物動起來
把最好的靜態圖變成影片。把一張肖像放進影片生成器的 Start frame 起始幀做出一個會動的鏡頭,或讓這個人物開口說話:生成一段配音,再驅動一個對嘴的數位人偶,讓嘴型對上台詞。Kling 3.0 在對嘴和對話上表現很強。參見圖片生影片指南。
她望向鏡頭,帶著溫暖的微笑說了聲哈囉,輕鬆而自然,頭部微微擺動。直式 9:16,5 秒。
第四步——賦予聲音並發布
挑一種語音並保持一致——聲音是身分的一部分。在 Studio 中組裝多鏡頭作品,加一層音樂鋪底,再匯出 9:16 用於 Reels / TikTok。
常見修復
| 問題 | 試試這樣做 |
|---|---|
| 臉在不同造型之間變了 | 用一張更清晰、正面打光的基底照片——Muse 守不住一張它看不清楚的臉 |
| 造型感覺很重複 | 抽一批隨機結果,或搜尋一個不同的關鍵字換來新鮮的預設 |
| 某個預設把臉扭曲了 | 在更換預設之前先換一張更乾淨的基底照片;源圖品質能解決的問題比挑預設更多 |
| 聲音每則貼文都不一樣 | 鎖定一種語音並每次都重複使用——聲音是身分的一部分 |
| 對嘴看起來不對 | 用一張清晰的正面肖像,搭配像 Kling 3.0 這類對嘴能力強的模型 |
| "Photos of real people aren't supported" | 某個影片模型的隱私過濾——改用 Kling 3.0 或 Veo 3.1 來讓真實的臉動起來 |
讓它長期保持一致
- 永遠從同一張基底臉孔出發,讓每一套造型都讀成同一個人。
- 重複使用同一種語音,以及定義你美學的那一小撮 Muse 關鍵字。
- 把你最好的造型存成參考,這樣每則新貼文都只差一次生成就能完成。
相關文章
- Muse 人像PonPon Muse 把一張自拍變成保留你五官的超寫實時尚人像。它的運作原理、八種風格、批次預設、雙人模式,以及如何拿到最佳成果。
- 會說話的虛擬人與對嘴在 PonPon 上讓一個角色開口說話:對嘴如何用一段音軌驅動 Kling 3.0 上的一張臉、聲音從何而來、一個實戰範例、源素材技巧,以及如何搭配配音轉譯。
- 圖片生影片指南讓你已有的靜態圖動起來:挑一張夠好的源圖、運用 Start 和 End frame、寫運動(而非場景),並在 PonPon 上為圖片生影片挑選最合適的模型。
- 圖片提示詞寫作一套實用的 PonPon AI 圖片提示詞方法:一個可靠的結構、從弱到強的改寫、模型能理解的風格與光線詞彙、參考圖片,以及問題修復。